

今天,咱们就开门见山啊。这一回要测一测,昨天才发布的文心一言大模型 4.0。
之所以要测它,是因为李彦宏昨天在会上说的那句:文心大模型 4.0 综合水平与 GPT-4 相比已经毫不逊色。

这话一出,很多人就沸腾了。
据李彦宏这边的说法,文心 4.0 在记忆、理解、逻辑和生成四块,进步神速。
尽管他也在现场亲自演示了很多案例,但很多用户是压根不买账的。
不少人调侃说:“ 骗骗兄弟就可以了,别把自己也骗了啊。 ”
那到底是毫不逊色,还是吹牛扯淡呢,咱们直接亲自试试就知道了。

这回,凭借世超的人脉,也是很幸运地拿到了抢先内测的资格。
既然他吹自己和 GPT-4 比毫不逊色,那我们就让这俩互掐一下,比比斤两。
从拿到资格开始,世超试了一整天。这次也不跟大家卖关子了,直接说测试结论:
总体来说, GPT-4 稳定胜利,但文心一言 4.0 居然意外地某些方面压过 GPT-4 一头。

那么世超这次测试,还是从比较常见的几个测评角度入手,这样体现的更全面、真实。但是,测试难度我们是和之前的 GPT-4 测评难度对齐的。
这比赛的第一轮,先测点大家喜闻乐见的吧。
先从比较轻松的弱智吧和语义陷阱题入手,也正好可以考察一下逻辑和理解能力。
不过,这块很多大模型都有专门训练,问了很多题都没把它们考倒。但是,经过不懈努力,还是被世超抓到了漏洞。
我问了一个非常经典的弱智吧问题:世界上真的有 “ 龙 ” ,那我就在某地被 “ 一条龙 ” 服务过。
没想到,这题两个 AI 没一个能做对的。。。
先看 GPT-4 这边,由于不知道这俩 “ 龙 ” 到底嘛意思,就开始乱编一些历史典故。
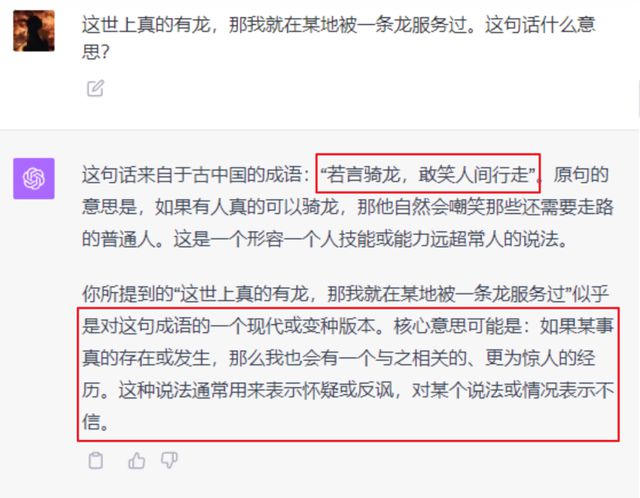
文心这边,也没有聪明到哪去,也是乱编了一种 “ 幽默 ” 的说法。
甚至,世超后面又给了它一次机会,追问它:两个龙是同一个龙吗?
文心依然极其坚定地给了我一个完全错误的答案。

不过,到了第二题, GPT-4 就站起来了。
当我问:公司是个温暖的大家庭,怪不得我总是当孙子。
文心这边还在那 “ 温暖的公司 ” 、 “ 没有等级差别 ” 。

但再看人家 GPT-4 这个外国 AI ,早就读懂了中国人的话里有话,表面温暖,实则冰冷。

不过,当世超又追加了一道领导题。事态却突然彻底反转,反而是文心赢得很彻底。
世超问了几个流行的段子: “ 领导夹菜你转桌,领导喝水你刹车 ” ,让它们给仿写几个。
其实这题要想做对,并不容易。不仅仅需要精准地理解提问,并且要能够推理出句子的规律和情感色彩。
两边 AI 给我的句子,对仗都蛮工整的,就是 GPT-4 语义彻底理解反了。领导的马屁拍的非常完美,可惜就是答案全错。
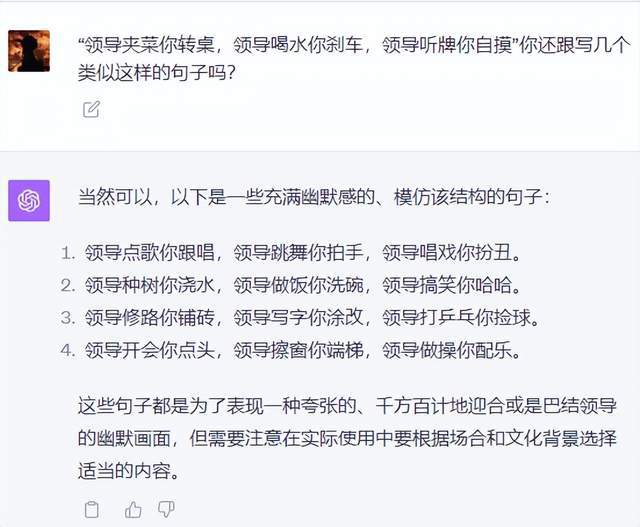
文心这边给的这些答案,才真的符合当代青年的领导文化。
不过温馨提示,实操的时候建议开始以 GPT-4 为准。

这第一轮比拼结束,文心 VS GPT-4 不分高下, 1 比 1 打了平手。
看来,文心一言说自己进步神速,不是完全在吹牛啊。
第二轮比赛,世超还想继续玩点有意思的,试试 AI 解读梗的能力。
当年, GPT-4 上线时能解梗图,那是叱诧风云了好长一段时间。
这一次,世超不仅仅让它们读梗图,还要加码测试一下,看他们联网能力能不能应对各种网络上的新梗。
因为前面都是测中文语义,世超觉得对 GPT-4 有点不公平,所以特地选了个中英注解都有的梗图。
就像我的人生一样
不知道在忙些什么

不知道是不是有英文辅助,这一次GPT-4 梗图解读能力强的不是一星半点。
不光能看懂 “狗狗” 是这张梗图的关键角色,而且读懂了笑点在于 “ 认真帮忙 ” 和 “ 毫无效果 ” 的对比。

但是,文心这边却还在一板一眼地把梗图,当阅读理解题来做。。。
而且嘴还蛮硬,你说这张图好笑,它坚持:这没啥让人发笑的,搞不懂你在乐什么。
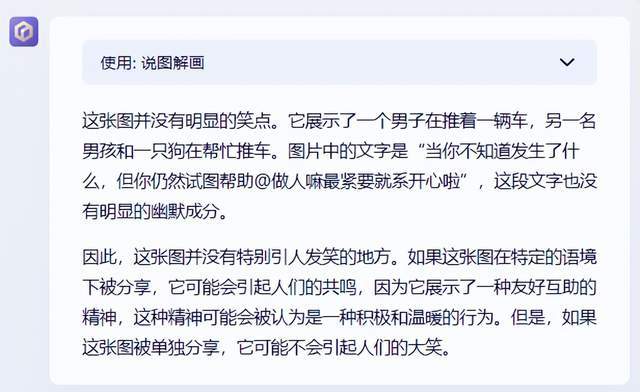
不过,文心虽然不擅长解释梗图。但到了中文互联网梗,又马上扳回了一城。
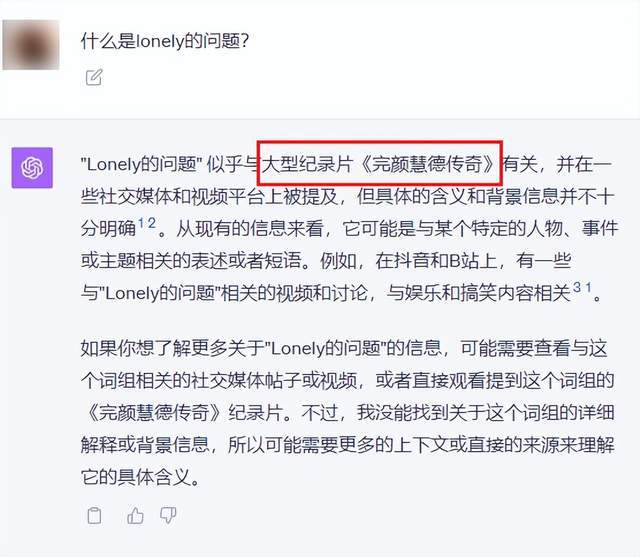
世超问了个关于最近互联网上的新晋网红完颜慧德老师的 lonely 梗。
这如果不是十级冲浪选手,一看到这个句子,估计是一脸蒙圈的。

结果,文心不光点出了梗来源,而且正确解释了这是个谐音梗。
虽然最后很可惜,把 “ 伦理 ” 错误理解成了 “ 理论 ”,就差这临门一脚,没踢进去。

但如果文心这边是没满分,那 GPT-4 这边恐怕属于不及格了。。
不光没读懂梗,连出处都找错了,让你去大型纪录片《完颜慧德传奇》里面找一找答案。
这第二轮比赛的两道小测试下来,双方各有千秋,不分高下吧。文心的热梗更新很快, GPT-4 图片解读更强。
两轮比赛下来,目前还没分出个高低来,焦灼在了 2 比 2 。
接下来,为了拉开比分的差距,咱们得上点狠货了。
前面两轮语义理解都更偏基础,我们再测试一下专业能力。第三轮直接顶上 GPT-4 的超级强项——代码题。
不知道还有没有人记得,当年 GPT-4 花了 60 秒,做出一个完整的贪吃蛇小游戏,震撼了整个江湖。
现在我们用同样的测试,让文心来试一下。
因为代码比较长,所以这里就不完全展示了。咱们可以直接划到下面,看最后的效果。

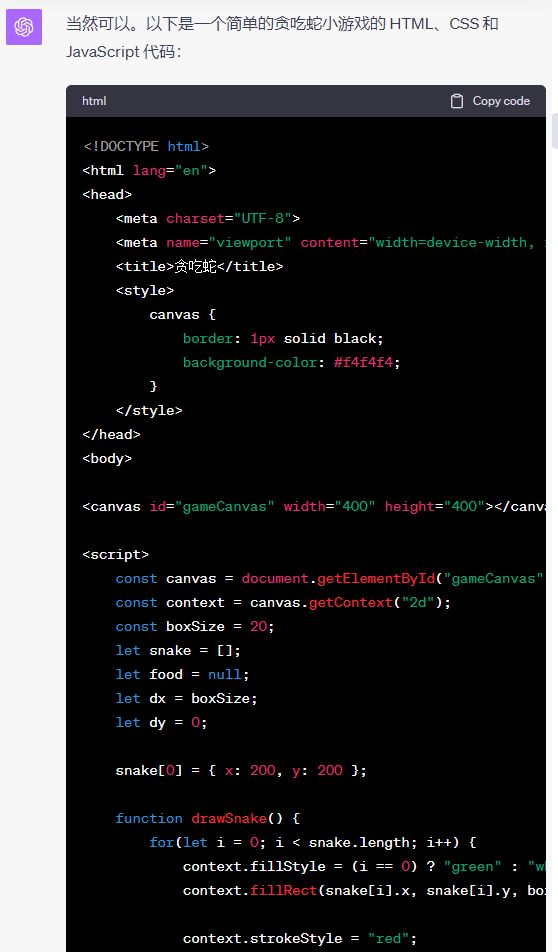
先来看 GPT-4 老大哥,依然是稳定发挥。大概几十秒,就做出一个完整的、可以玩的贪吃蛇游戏。包括蛇的移动、点的随机出现、吃完后体积增大这些效果。

但是,来到文心这一边,就是彻底不及格了。
不说别的,这贪吃蛇根本就没动起来,而且后面试着让文心自己修正代码,结果也是越改越错。
这不是动图没动,是文心就没做出动的效果来

不过,也不代表文心就很拉,这样悬殊的实力差距,其实是因为 GPT-4 的代码能力太变态了。
如果我们稍微降低一点难度,让它们根据草图,来做网站,那文心也是能自如应对的。

但是,尽管这样,从下面两个网站的效果比较来看, GPT-4 还是更精美、更完整。
文心一言

GPT-4

这第三轮的比赛, GPT-4 是毫无疑问地全面吊打了。现在比分也被拉开了,文心 VS GPT-4 = 2:3 。
为了避免不公平,既然前面试了一个 GPT-4 的强项,那接下俩也测一个文心说自己比较厉害的能力——记忆。
世超找了一份曾经采访导盲犬相关人士的采访文件,全采访资料总共有一万三千多个字。

把这一大份文件丢给这俩 AI 之后,我问了一个最简单的问题:
为什么说导盲犬是骗局?
让人有点意外的是, GPT-4 虽然答案是对的,可是分析得牛头不对马嘴。
我问骗局的原因,他和我说训练难度和导盲犬的导盲能力。。

反倒是文心这一边理解的很准确,它回答的成本高、夸大宣传、不如导盲设备前景好等等,这些才是关键信息。

文心在记忆和理解方面,确实挺扎实。算是成功扳回一城,把比分重新拉回到平局 3 :3 。
既然事态这么胶着,那这最后一轮,我们就再试一个比较有意思的题。
之前 GPT-4 Vision 版提过,这一代的 GPT-4 图片识别能力很强,可以给合照里的单人进行标注、给图片排序等等。

前面好几道试题,已经证明了文心的图片识别能力也完全不弱。所以,这最后一题,咱们就用图片来一决高下。
世超丢了一张牙齿的 X 光片进去,让双方给我当医生,诊断诊断病情。
俩 AI 都诊断出了存在的智齿阻生问题,而且 GPT-4 甚至看出了上排牙齿存在不整齐的问题,有三颗牙齿是重叠状态。
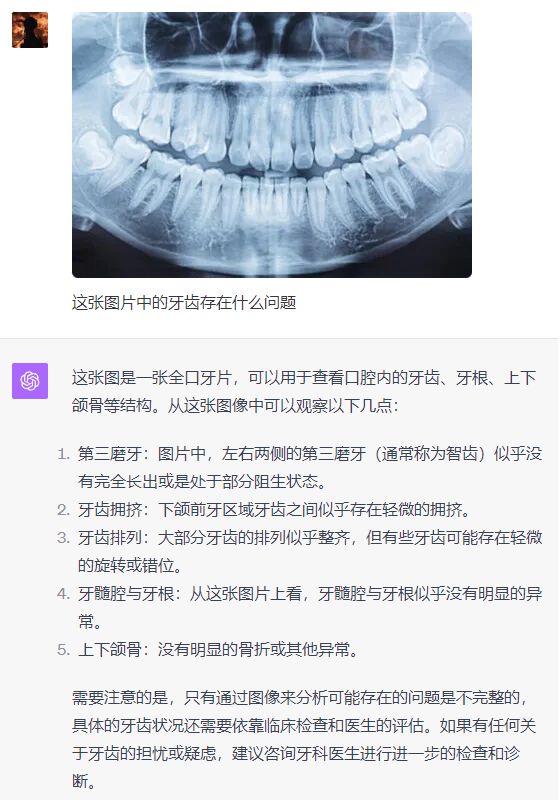
虽然文心一言也发现了智齿阻生的问题,也指出了可能存在的其他问题。但还是 GPT-4 的答案更准确,更贴切。

这五轮比赛结束,文心一言还是 3:4 输给了 GPT-4 ,在代码这方面,更是被狠狠吊打了。。但在中文语义理解和记忆这些方面,也确实如百度所说,提升了不少。
除了上面我们这些基础测试,这次文心一言还上线了好几个插件功能。
比如一镜流影( 视频生成 )、说图解画( 图片解读 )、 E 言易图( 可视化数据分析 )

比如说一句话做一个金毛爬楼梯的视频,几分钟之后一条配好音的视频就做好了。
不过,目前也不是非常完善,经常出现素材不够,无法生成视频的情况。
作为一个玩具体验一下,还是挺有意思的,真当生产力工具,多少有点够呛。

虽然如此,但文心 4.0 的表现已经让我眼前一亮了。
说实话,原本世超并不对文心抱有太大的希望。因为 GPT-4 的强悍,大家都有目共睹。
在这么强的对手面前,很容易显得你的努力都白费了。。。
这回尽管还是输了,但起码你能感受到进步的地方,更擅长的领域。
不过,最后还是要强调一下,世超的测试只能从常规的角度来简单对比两个大模型。只能算带大家尝个鲜,抢先体验一下,并没有办法,完全代表大模型的实力情况。
到底几斤几两,还需要等彻底开放之后。大家亲自上手体验,才会有更深的感受。





