(编辑/吕栋)
9月25日,阿里云开源通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费可商用。据介绍,Qwen-14B在多个权威评测中超越同等规模模型,部分指标接近Llama2-70B。就在一个多月前,阿里云开源70亿参数模型Qwen-7B等,下载量已破百万。
Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推理、认知、规划和记忆能力。Qwen-14B最大支持8k的上下文窗口长度。Qwen-14B-Chat是在基座模型上经过精细SFT得到的对话模型。借助基座模型性能,Qwen-14B-Chat生成内容的准确度大幅提升。
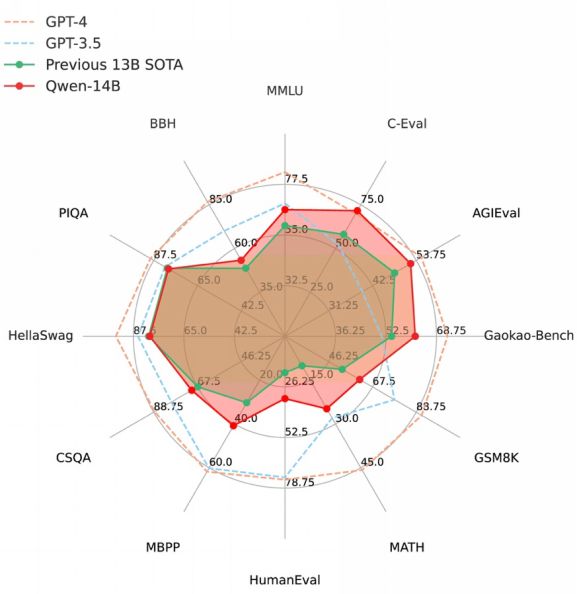
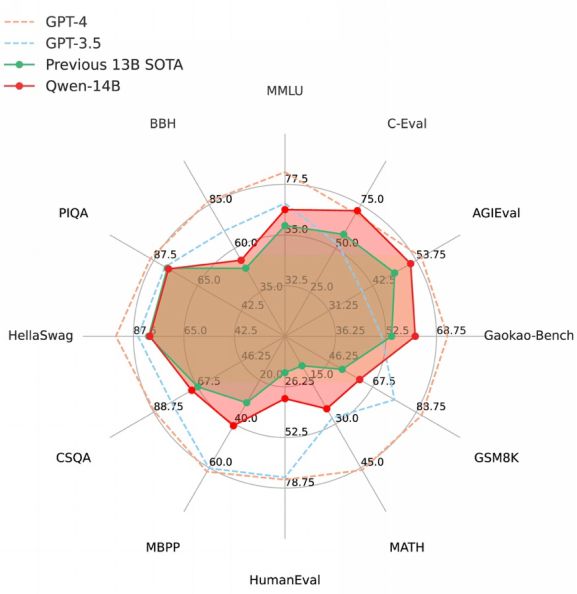
Qwen-14B在十二个权威测评中全方位超越同规模SOTA大模型
阿里云表示,Qwen拥有出色的工具调用能力,能让开发者更快地构建基于Qwen的Agent(智能体)。开发者可用简单指令教会Qwen使用复杂工具,比如使用Code Interpreter工具执行Python代码以进行复杂的数学计算、数据分析、图表绘制等;还能开发具有多文档问答、长文写作等能力的“高级数字助理”。
百亿以内参数级别大语言模型是目前开发者进行应用开发和迭代的主流选择。阿里云透露,Qwen-14B进一步提高了小尺寸模型的性能上限,在MMLU、C-Eval、GSM8K、MATH、GaoKao-Bench等12个权威测评中取得最优成绩,超越所有测评中的SOTA(State-Of-The-Art)大模型,也全面超越Llama-2-13B,比起Llama 2的34B、70B模型也并不逊色。与此同时,Qwen-7B也全新升级,核心指标最高提升22.5%。
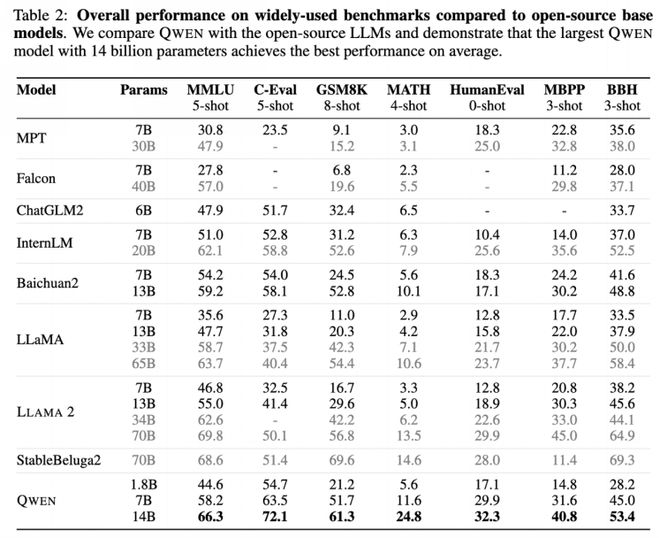
Qwen-14B性能超越同尺寸模型
目前,开源是国产大模型的主流选择。《中国人工智能大模型地图研究报告》显示,超过一半国内发布的大模型已实现开源,并朝着通用类大模型和垂直领域的专业类大模型两个方向加速迭代。除了通义千问外,由王小川创立的人工智能创新科技公司百川智能也在一个月间将通用类开源模型参数规模翻倍。其在今年6月推出70亿规模参数的Baichuan-7B开源模型后,又在7月开源拥有130亿的参数规模的Baichuan-13B模型。
专业类大模型则受行业数据、适用程度等制约,开源模型参数规模差异较大。在搜索场景,知乎已于今年5月开源有100亿参数规模的CPM-Bee 10b。而在金融行业,度小满在9月才开源拥有70B参数量级和上下文长度可达8k以上的金融大模型“轩辕70B”。
有业内人士指出,在一些垂直领域并不需要参数量很高、通用能力很强的模型,几十到百亿左右参数规模的模型,结合垂直领域数据,就可以发挥很好的价值。对行业而言,开源大模型可以帮助用户简化模型训练和部署的过程,用户不必从头训练,只需下载预训练好的模型并进行微调,就可快速构建高质量模型。这正是开源大模型推动各行业发展的底层因素。
阿里云CTO周靖人表示,阿里云将持续拥抱开源开放,推动中国大模型生态建设。阿里云还牵头建设了中国最大的AI模型开源社区魔搭ModelScope。过去两个月内,魔搭社区的模型下载量从4500万飙升到8500万,增幅接近100%。